Dify 1.12.0:摘要索引——从碎片化检索到全上下文理解
摘要: Dify 1.12.0 引入的 Summary Index(摘要索引)解决了传统分块检索在文档总结场景下的局限。通过为每个数据块附加摘要字段,该功能实现了语义相关内容的批量召回,显著提升了 LLM 处理概括性查询时的上下文完整性与回答质量。
在知识库问答场景中,用户的问题通常分为两类:
1. 具体查询:例如“退货政策是什么?”
2. 总结请求:例如“请给出这份文档的关键要点。”
传统的基于分块(Chunk-based)的检索方式擅长处理第一类具体问题,但在面对第二类总结需求时往往力不从心。原因很简单:一旦文档被拆分为独立的片段,每个片段就彼此孤立了。传统检索仅返回最相关的那一个碎片,导致模型缺乏足够的上下文来生成完整的答案。
GraphRAG 通过构建实体关系图来解决这一问题,但其实现复杂度较高。Summary Index(摘要索引)是 Dify 1.12.0 推出的一种轻量级替代方案:它通过在每个数据块上附加“摘要”字段,使得语义相关的内容能够被一起检索出来。
Summary Index 的工作原理
Summary Index 为每一个数据块添加了一个 summary(摘要)字段。
假设有一篇技术文档,包含三个分别涉及架构设计、性能优化和部署流程的数据块。在传统模式下,这些数据块是独立存储和检索的。而在 Summary Index 中你可以让这三个数据块共享同一个摘要,例如:
“系统技术方案概览”
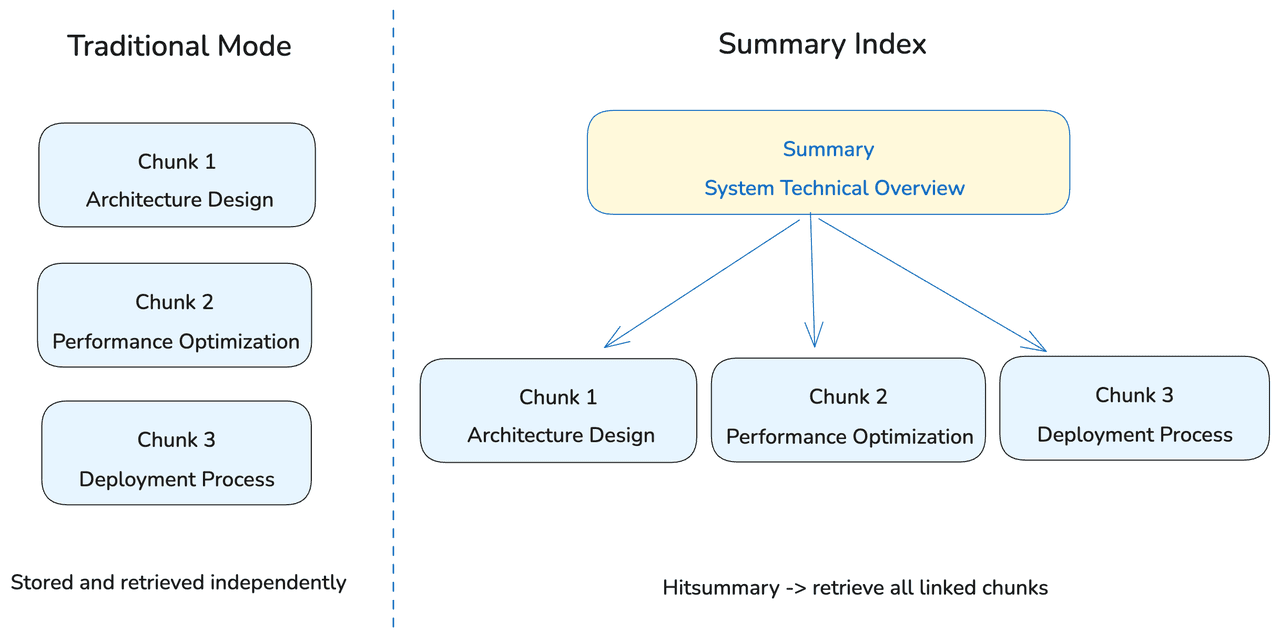
此时,数据块内容和摘要内容都会被向量化并存储在数据库中。在查询时,用户的问题会同时与这两者进行匹配:
* 如果直接命中某个数据块的内容,则返回该数据块。
* 如果命中的是摘要,则会检索出所有拥有相同或语义相似摘要的数据块。
总结类问题更有可能匹配到摘要中更高层级的语言描述。这意味着模型将获得更完整的上下文信息,从而生成更好的答案。
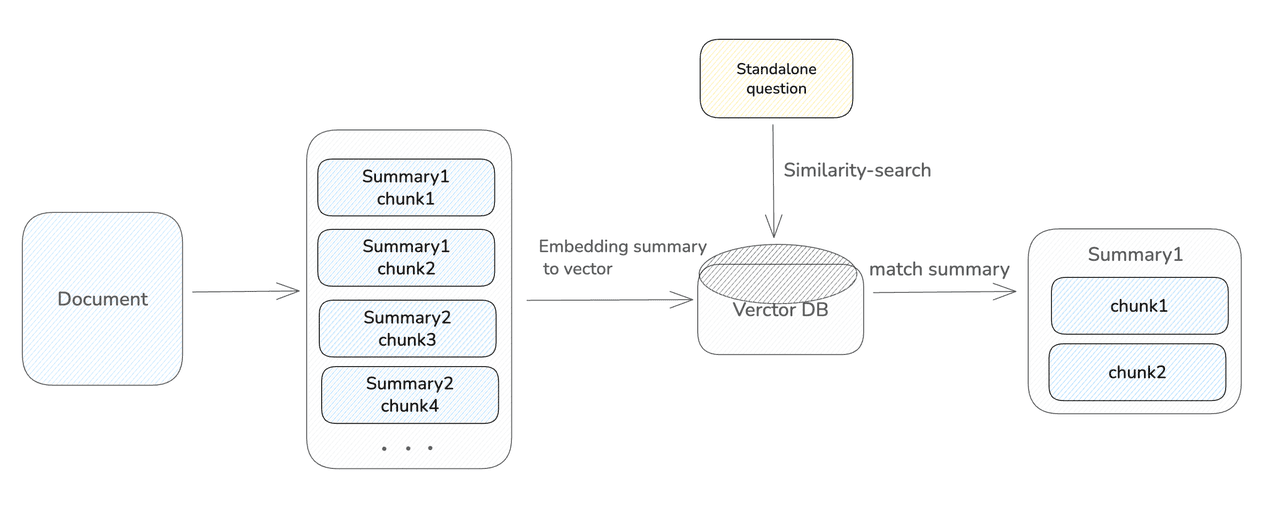
如何添加摘要
Dify 提供了三种方式为数据块附加摘要:
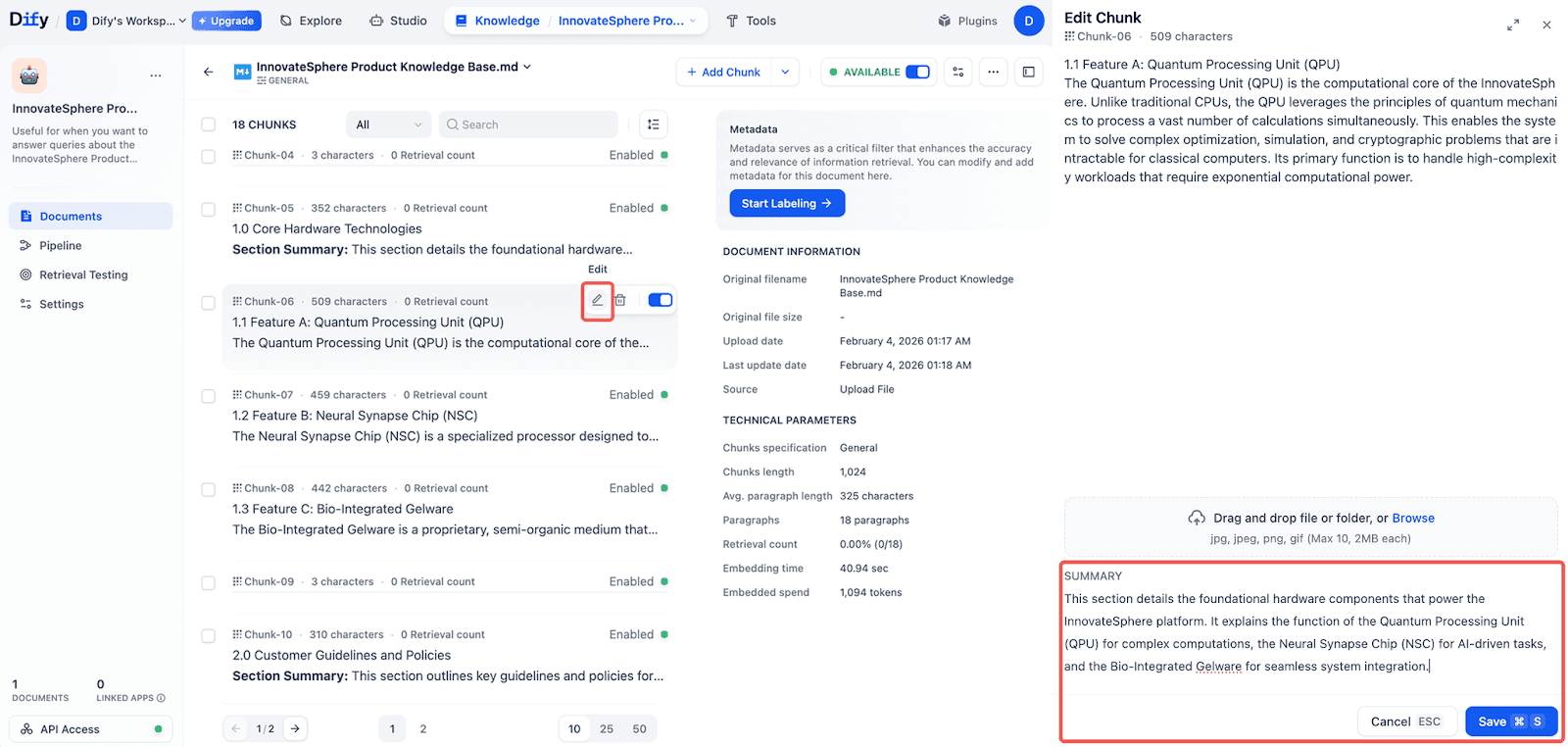
1. 手动编辑
知识库的数据列表现在包含一个 summary(摘要)字段。你可以直接针对单个数据块进行编辑。
2. API 导入
Dify 1.12.0 的服务 API 支持 summary(摘要)字段。如果你的文档已经包含结构化的摘要信息(例如论文摘要或研究报告的执行摘要),可以通过 API 批量导入,并将每个摘要与其对应的数据块关联起来。
查看 API 参考文档:
知识库 API 文档
3. 自动生成
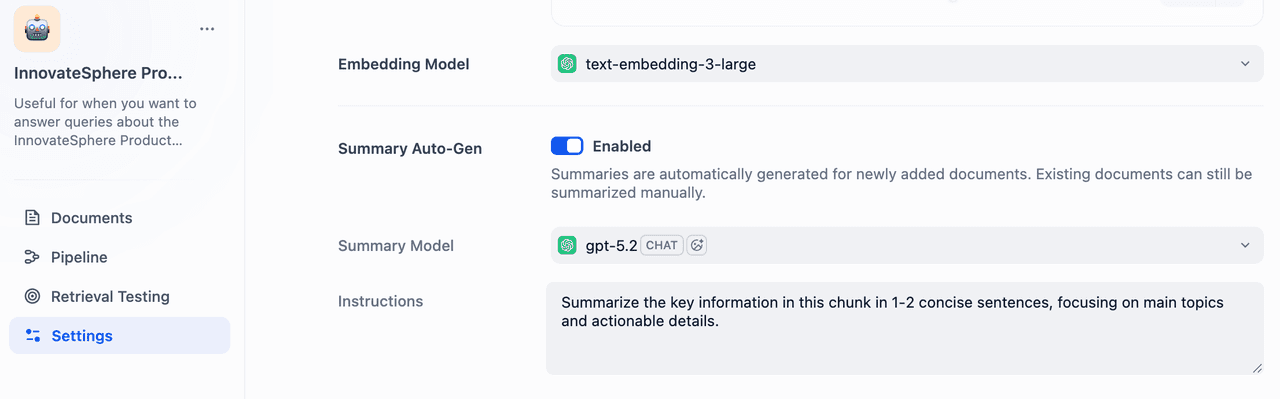
社区版用户在创建知识库时,可以启用“自动摘要生成”选项。选择 LLM 模型并提供指令后,系统会自动为每个数据块生成摘要。对于已有的知识库,你可以从文档列表中选择文档(支持多选),并批量生成摘要。由于摘要质量直接影响检索效果,我们建议对自动生成结果进行人工审核。
验证与集成
配置完成后,请使用知识库中的 Retrieval Testing(检索测试)功能来验证摘要是否按预期工作。
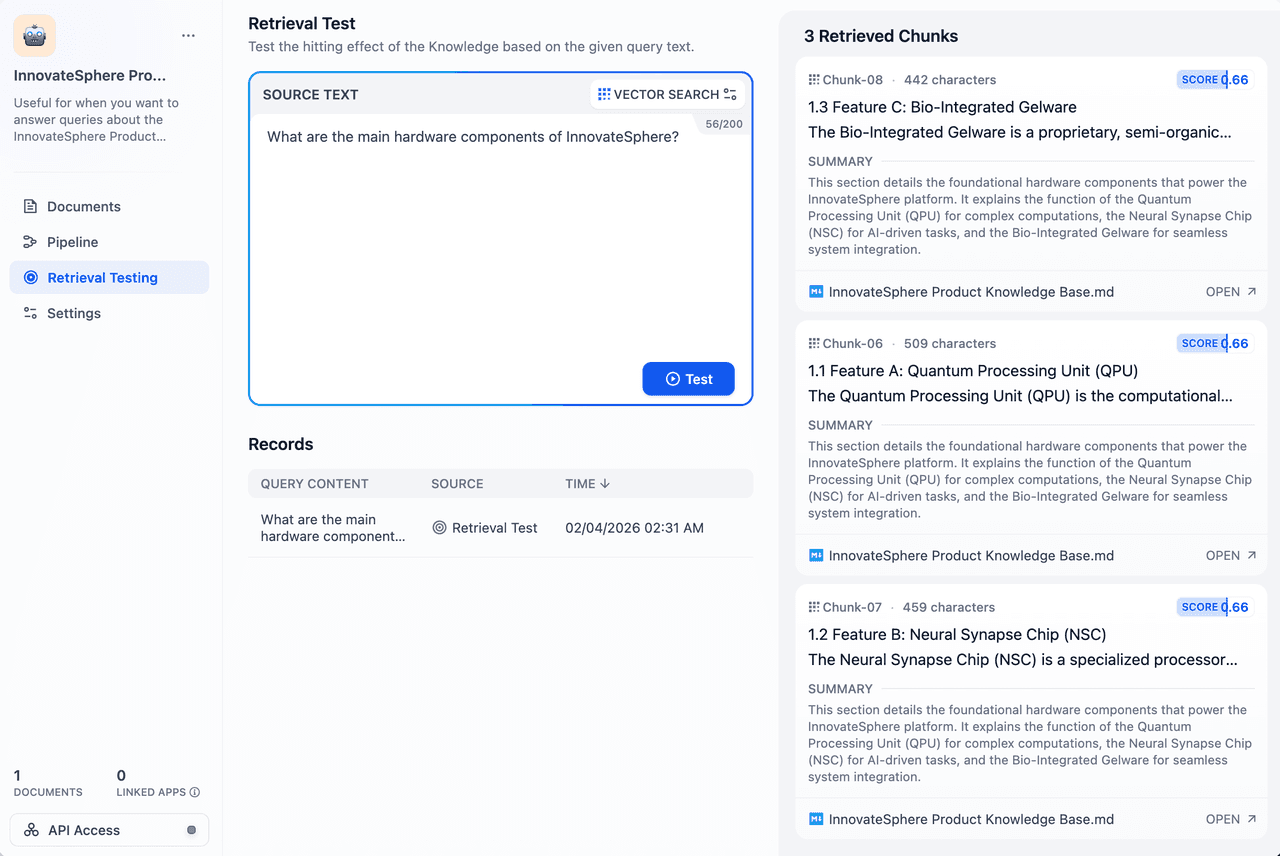
例如,在产品知识库中输入:
“InnovateSphere 的主要硬件组件有哪些?”
系统同时返回了三个数据块。每个数据块涵盖不同的组件(QPU、NSC 和 Gelware),但它们共享相同的摘要。这证实查询命中的是摘要而非单个数据块。此时 LLM 拥有了全局视角,从而减少了不完整或片面的回答。
如果检索结果不符合预期,请检查:
1. 摘要的措辞是否足够通用?
2. 摘要在语义上是否与预期的用户提问类型接近?
在工作流(Workflows)中,Knowledge Retrieval(知识库检索)节点也支持 Summary Index。当匹配到摘要时,所有关联的数据块将被返回,并可直接作为上下文传递给 LLM 节点。
何时使用 Summary Index?
1. 内置摘要的文档
学术论文、行业研究报告和技术白皮书通常自带摘要或执行概要。这些内容几乎无需额外努力即可直接写入对应的数据块中。
2. 频繁的总结类查询
当用户经常提出如“关键要点是什么?”或“能总结一下吗?”这类需要跨片段回答的问题时,Summary Index 能显著提升响应质量。
3. 致力于数据治理的团队
摘要的撰写或审核需要人工参与。如果你的团队重视知识库的质量,Summary Index 提供了一个新的优化维度。
结语
知识库检索的核心挑战之一,是在文档拆分后保留内容板块之间的语义关联。Summary Index提供了一种轻量级解决方案:在不改变分块逻辑的前提下,在数据块之上增加了一层摘要层,使得相关内容能够在检索时被重新组装。
Summary Index现已在 Dify 1.12.0中可用。
查看完整文档以获取设置详情:Summary Index Documentation
为数据块添加摘要字段,提升你的 AI 处理总结类查询的能力。